
“Data Scientist: The sexiest job of the 21st century” was the title of an article published in the Harvard Business Journal in 2012. That’s all well and good, but what does a data scientist job profile look like? Can you imagine what it entails in concrete terms?
Who is this article for? For anyone interested in working as a data scientist in a company or institution. But also for those already employed in the field of data science who want to compare their actual to-do lists with the typical tasks. Because sometimes the activities stray too far into other data professional job profiles, so that it is no longer really a data science job.
Let’s explore a typical data scientist job profile.
Table of Contents
What is not a data scientist?
- Not “just” a Data Analyst, who rarely build predictive models or use machine learning and interpret historical data to identify trends.
- Not a Data Engineer, who build and maintain the data infrastructure like pipelines, warehouses, APIs. Data Engineers focus on data architecture and reliability, not on modeling or insights.
- Not a Software Developer, who typically build full-scale software products or maintain production systems.
- Not an AI Researcher, who invent AI/ML algorithms, and their work is located between research and business application
- Not a Business Analyst, who concentrate with their work on process optimization, requirements gathering, and project alignment with business goals.
- Not “just” a Statistician, who work with much smaller and cleaner datasets
What is a typical data scientist job profile?
Your job is to solve real company problems using data. The company or institute wants solutions from you so that important business decisions can be made.
Data Science Skills
Surprise! You need skills. Without the following expertise, you cannot succeed in this highly competitive and demanding field. The opportunities with a educational degree are much higher than without one. A degree like computer science in particular is a typical highly relevant one.
Statistics and Mathematics
Statistics is one of the most important foundations for the job profile. If you want to model the relationship between one dependent variable and one or more independent variables, then linear regression is the statistical technique for you. Your skills should go beyond basic knowledge of statistics.
Machine Learning

Machine learning is already integrated into numerous online applications without us even noticing it. Take recommendation algorithms in online shops, for example, such as “XYZ might interest you because you bought ABC.” Important data science methodologies originate from machine learning.
Coding: Python, R

Without the programming languages Python or R, the data scientist job profile simply doesn’t work. You don’t have to write huge programs like a software developer, but with Python you can do cool things in Jupyter Notebook.
SQL (Structured Query Language)

SQL is not a programming language like Python, Java, or C++. It is a structured query language that facilitates the management of large amounts of data. Experience with data manipulation: SQL should be included in every data professional toolbox.
Algorithms
Machine learning algorithms are important skills for this job profile. Here are some important algorithms: Random Forest, Linear & Logistic Regression, Naive Bayes, Decision Trees, K-Nearest Neighbors (KNN) or Support Vector Machine (SVM).
Tools & Frameworks

The following list of data science tools should motivate you to conduct further online research on the individual tools. This will familiarize you with tool terminology, which can be daunting for beginners due to the many unfamiliar terms used in job advertisements. Important tools: Python, R, Jupyter Notebook, TensorFlow, Scikit-learn, Matlab, Matplotlib, Github, Docker, Apache Spark, Apache Hadoop, The Natural Language Toolkit (NLTK), WEKA, D3.js, KNIME, SAS, Tableau, Power BI, Excel, Numpy, Pandas, Keras, Kibana, IBM SPSS, Scrapy, RapidMiner.
Communication & Presentation

What good are the most groundbreaking insights from your data if your stakeholders can’t do anything with them because they don’t understand them? In order to receive the appropriate appreciation for your demanding work, clear, straightforward communication and exciting presentation techniques are essential. Communicating insights to both technical and non-technical stakeholders is your key to be valued.
The Data Science Hierarchy of Needs
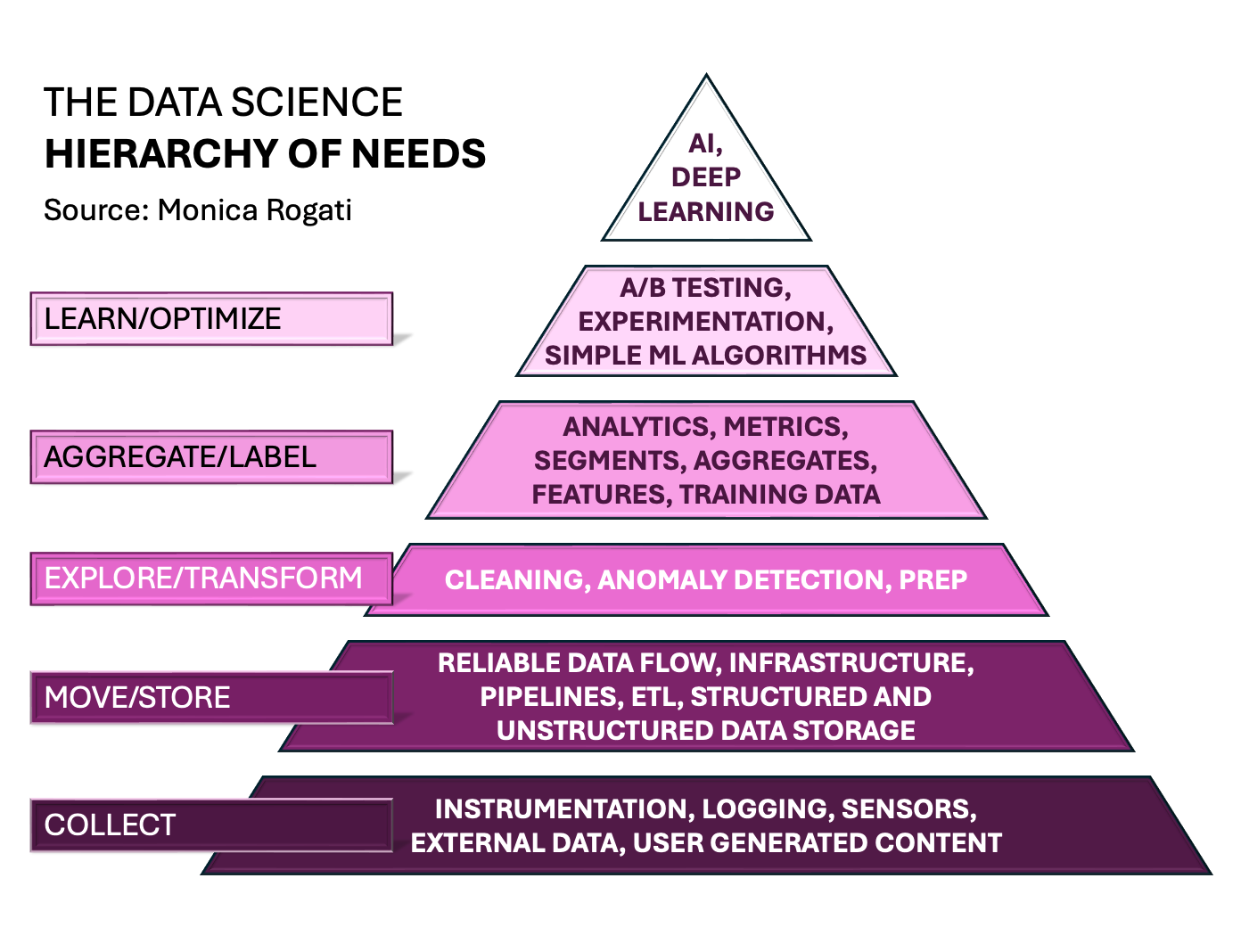
The pyramid shows the sequence of activities in data science.
Collecting Data
First, at the bottom, we have the foundation: data collection. Without these data, we have nothing to build on. Where do the data come from? The Sources are: User generated Content, sensors, logging, digitization of analog data, and so on. Only if data collection was accurate, reliable, and complete can the company move on to the next level in the pyramid.
Moving, storing
How does the data flow and where is it stored? These are questions that are answered and implemented with the help of the “Move/Store” layer. Is the data stream / ETL (Extract, Transform, Load) reliable? Is it easy to access and analyze the data?
Exploring, Transforming
In an ideal world, data is clean and there are no anomalies. For Monica Rogati, author of the article “The AI Hierarchy of Needs,” this is where, among other things, the lack of data and the unreliability of sensors are identified. And then it goes back to ensure a solid foundation for the pyramid.
Aggregating, Labeling
Once you can reliably interpret and clean up data, the classic analytics process starts: Specify metrics, examine seasonal trends and influencing factors, and create initial user segments.
You are developing potential features for a later machine learning model. You now also understand what you want to predict and can start preparing your training data with labels.
Learning, Optimizing
Even with training data, machine learning isn’t immediately ready. Before deployment, you need a basic A/B testing system to step by step roll out changes and monitor their impact. Initial values help measure future improvements.
AI & Deep Learning on the top
You have reached the top of the pyramid. You’re ready: clean data, tested algorithms, and daily experiments are in place. Now explore new ML tools – either custom-built or via experts. Even if refinements are small, you’ll grow experience and confidence with clients and stakeholders.
What are your responsibilites?
What your tasks ultimately are depends on the company. If it’s a start-up,
Startup

Your responsibilities will start at the bottom of the pyramid with data collection and goes up to the “Learning / Optimizing”. Oops! You’ll have to do almost everything yourself.
Medium-Sized Company

Medium-sized companies have more resources for personnel costs than startups. This often results in the following division of the pyramid layers. The “collecting” layer is handled by software engineers, while the “moving/storing” and “exploring/transforming” layers are the responsibility of data engineers. You handle then the top three layers, “aggregating/labeling,” “learning/optimizing,” and “AI, deep learning,” at the very top of the pyramid.
Large Company

Large companies and corporations can significantly spend more money and have therefore enormous capacities for data professionals. In a big company you can take it out to focus on a topic you are most passionate and interested in.
If you are most interested in training data, you don’t have to worry about the other responsibilities, you can focus only on this. The first three layers from the bottom of the pyramide are similar to these in a medium-sized company. You are often responsible for the second and third layers of the pyramid from the top.
In large companies, for AI, Deep Learning on the top layer there have following roles responsibility: Research Scientists, Data Core or Machine Learning Engineers.
How the data scientist role differs from other related data professionals
Although Data Scientists, Data Analysts, and Data Engineers all work with data, their core functions differ:
| Profession | Primary Focus | Key Skills | Typical Tools |
|---|---|---|---|
| Data Analyst | Examining historical data for trends | SQL, dashboards, reporting | Excel, Tableau, Power BI |
| Data Engineer | Building and maintaining data pipelines | Databases, cloud infrastructure | Python, Spark, AWS, Kafka |
| Data Scientist | Building predictive and ML models | ML, statistics, Python, data wrangling | Python, R, scikit-learn, TensorFlow |
Conclusion
Your responsibilities will depend largely on the size of the company. In start-ups, you may be responsible for everything from collecting data to designing machine learning algorithms. This can lead to a very high workload and stress in the long run.
Ask about the exact scope of your responsibilities during the interview. When it comes to the employment contract, it would be good to have the areas of responsibility specified.
Take the opportunity to choose your data science niche as early as possible – be it natural language processing (NLP), computer vision, or time series forecasting. The key is to find an area that you are passionate about. This will give you the energy you need for one of the most challenging and exciting jobs in IT.
References
[1] 13 Essential Data Science Tools (And How to Use Them). (n.d.). 13 Essential Data Science Tools (and How to Use Them). https://learning.linkedin.com/resources/learning-tech/how-to-use-13-essential-data-science-tools
[2] Hr, & Hr. (2023, May 29). What’s a data scientist? Explaining roles in big data | Hibernian Recruitment. Hibernian Recruitment | Personalvermittlung in KI, Data Und Sales. https://www.hibernian-recruitment.com/en/whats-a-data-scientist-explaining-roles-in-big-data/
[3] Winter, J. (2025, February 23). Data engineer vs. data scientist vs. data analyst — Jeff Winter. Jeff Winter. https://www.jeffwinterinsights.com/insights/data-engineer-vs-scientist-vs-analyst
[4] Eland, M. (2021, November 15). Roles in Data Science. Matt on ML.NET. https://accessibleai.dev/post/datascienceroles
[5] Hayes, B. (2015, September 23). Investigating Data Scientists, their Skills and Team Makeup |. https://businessoverbroadway.com/2015/09/23/investigating-data-scientists-their-skills-and-team-makeup/
[6] Rogati, M. (2017, June 12). The AI hierarchy of needs. HackerNoon. https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
[7] Davies, L. (2024, April 1). What is the hierarchy of needs in data science? – Noodle.com. Noodle.com. https://resources.noodle.com/articles/data-science-hierarchy-of-needs/
[8] Joma Tech. (2018, June 23). What REALLY is Data Science? Told by a Data Scientist [Video]. YouTube. https://www.youtube.com/watch?v=xC-c7E5PK0Y